Growth in Hybrid Cloud
It is probably no surprise to anyone reading this that the move to Hybrid Cloud is picking up pace. IT organizations are moving data and workloads offsite for protection or to expand resource capacity more dynamically without increasing their capital spend. Of course, protection and capital management are just a couple of examples. The reasons and use cases for the growth of Hybrid Cloud are evolving nearly as fast as the technology that makes the hybrid infrastructure more viable than ever before.
As a storage focused Solution Architect, my perspective is data-centric. I look for ways to get data to the cloud most efficiently. My interests are motivated by how we use, migrate, and protect that data once it’s there. I need to answer questions about presenting the data to applications and compute resources, how to migrate it from one Cloud provider to another, and how to restore it back to on-premise resources.
Options for Managing Data in a Hybrid Environment
Management of data in a hybrid environment is facilitated by an increasing number of solutions today. This week, I’d like to highlight three cloud-based data solutions from Hewlett Packard Enterprise (HPE). Two of the HPE solutions I’ll be summarizing here are part of an HPE Cloud Suite. Those solutions include HPE Cloud Volumes Block and HPE Cloud Volumes Backup. The third solution has been around for some time and is not officially considered part of the Suite. However, I think it is important as a consideration in an overall Data in the Cloud strategy. That third solution is HPE Cloud Bank Storage.
The HPE Cloud Suite
As I mentioned before, the HPE Cloud Volumes Suite consists of a pair of enterprise-class, on-demand data services from HPE that provide Block and Backup storage on an HPE Cloud platform. Each of these services leverage technologies from HPE that can also be found in their on-premise solutions. Cloud Block utilizes Nimble Storage and Cloud Backup utilizes the StoreOnce Catalyst Store.
Together, these services can provide an on-premise experience. But, to be clear, you don’t need to have Nimble or StoreOnce on-premise in order to use these HPE data services. The idea behind Cloud Volumes is to provide access to your data from anywhere and allow you to move data between workloads across the major cloud providers that include Azure, Amazon Web Services (AWS), and Google Cloud Platform (GCP).
The HPE Cloud Volumes Suite is a pay-as-you-go service. You only pay for what you use. Because your data is on an HPE platform, you don’t need to worry about egress fees as you would with the other cloud providers. However, because the HPE platform has data locality beside the other service providers, you can present your data to compute resources located on the other platforms. This means you can move data between the other cloud services providers quickly and without additional charges. The result is the elimination of cloud provider lock-in.
So, let’s take a quick look at each of the Suite data services.
Cloud Volumes Block:
This service provides enterprise cloud-based Block storage to use for volumes that will connect to workloads running in Azure, AWS, and GCP. The storage is located on HPE’s cloud platform but with data locality near the cloud provider(s) of your choice. Because HPE Cloud Volume Block is separate from the workload platform, you can migrate data from one provider to the other without egress charges; the data doesn’t change its location, only the workloads change locations.
As mentioned earlier, HPE Cloud Volumes Block uses HPE Nimble technology and all the features you’d expect on that array platform. And, as with HPE Nimble on-premises solutions, you can expect six 9’s (99.9999%) availability with HPE Cloud Volumes Block. While the management interface is different than the on-premise Nimble Array, the ease of provisioning volumes still exists.
Using the HPE Cloud Volumes Portal, you can choose your Workload Cloud Provider, Cloud Application, Volume Type, Performance Characteristics, Size and Application Hosts to which you will present volumes. And, of course, you can specify snapshot schedules, whether to encrypt the volume, cloning, etc.
Features of HPE Cloud Volume Block include:
- Multi-cloud (AWS, Azure, GCP)
- Instant Snapshots and Clones
- 256-bit volume encryption
- Nimble replication from on-premise to Cloud
- REST API
- CLI
- Container support (Docker, Kubernetes, Mesophere)
- SoC2 Type 1-certified
- HIPAA-compliant
So, what are your workload requirements? Test/Dev? Production? HPE Cloud Volumes Block is suited for either of these use cases.
Cloud Volumes Backup:
As the name implies, this part of the HPE Cloud Volumes Suite provides a cloud-based backup target. We are all familiar with the 3-2-1 backup/recovery strategy where you maintain 3 copies of your data on 2 types of media with 1 copy off-site. HPE Cloud Volumes Backup fulfills the off-site part of that strategy.
The HPE Cloud Volumes Backup service integrates with some of today’s leading backup ISV’s, including Commvault, Veeam, and Veritas. There is also support for MicroFocus Data Protector. What this means is that you can start using Cloud Volumes Backup immediately if you already use one of these ISV backup/recovery solutions. In addition to the ISV’s mentioned, Cloud Volumes Backup integrates with HPE RMC (Recovery Manager Central) for protection directly from on-premise HPE Primera, HPE 3PAR, and HPE Nimble. But, to be clear, if you are using a supported backup/recovery software solution, you can protect data on any storage array supported by the ISV.
One of the goals for any backup/recovery strategy these days is to provide an extra layer of protection from a Ransomware attack. After all, it is reported that there is a ransomware attack happening every 40 seconds. To provide protection from ransomware, HPE Cloud Volumes Backup incorporates the HPE Catalyst protocol. This protocol creates data Stores that are not directly accessible by the OS, making the backup images invisible and inaccessible to ransomware.
With high-profile reports of data loss and increasing levels of government legislation for data security, companies are seeking to encrypt their data. With Cloud Volumes Backup, data is encrypted in-flight and at rest. Data on the wire travels under an AES-protected SSH tunnel to HPE Cloud Volumes Backup. Data at rest can be encrypted with 256-bit AES-encryption.
And, in case you were wondering, HPE Cloud Volumes Backup offers built-in multitenant security. Backup volumes created by one user are not visible to others, even if they are stored on the same device. Management or provisioning access, as well as data access, is also multitenant.
In addition to security, you are also likely concerned about being able to assure the integrity of the data you are trying to protect. The reliability of your backed-up data sets is critical. It would be a disaster to restore your data from a backup location only to find it is corrupt. HPE Cloud Volumes Backup provides data integrity throughout its lifecycle by providing built-in protection that checks data at multiple stages. Data is checked during backup, while at rest, and during recovery.
Finally, in addition to being ready in the event of a data recovery event, where you would be restoring data back to your on-premise array, HPE Cloud Volumes Backup can be used to restore data to HPE Cloud Volumes Block. It leverages public cloud compute resources for disaster recovery, test/dev, reporting, analytics, etc.
Cloud Bank:
So far, we’ve talked about cloud-based storage for production and test/dev workloads as well as storage for your off-site, standard retention backup target. An important consideration for any backup/recovery strategy is how you will manage your long-term, archive storage. To that end, HPE Cloud Bank is designed to be used as long-term archive object storage.
Cloud Bank is an extension to the HPE StoreOnce Backup Appliance. The design assumes you will store short-term retention data on an on-premise HPE StoreOnce appliance. Then, it tiers that data to HPE Cloud Bank for longer-term retention and archival data. Cloud Bank leverages a customers’ provisioned object storage in either Azure or AWS. It funnels data to and from those objects stores through StoreOnce.
In contrast, HPE Cloud Volumes backup is an as-a-service offering. A customer can have backups near to the cloud without managing a cloud infrastructure, or any on-premises appliances or licenses. You can also restore from Cloud Volumes Backup directly to any array, or, to Cloud Volumes Block, so that data can be used with GCP, AWS, or Azure compute.
Depending on your use case, all three of the cloud-based storage solutions presented here may work for you. Whatever you are looking to achieve with your cloud-based data footprint, one of these options is likely to get you there.
Contact Zunesis for more information on how to manage data in a hybrid cloud environment.
HPE Primera
Last week, Hewlett Packard Enterprise introduced their new product- Primera. It’s a high-end storage platform which helps to redefine what is possible in mission-critical storage. The product combines the intelligence technology from the Nimble family of arrays with the reliability of the 3PAR array family.
Primera is ideal for mission-critical applications and large-scale consolidation for enterprises. Whereas, HPE Nimble Storage is suited more for business critical applications for small and medium enterprises.
3PAR customers will find that Primera does not support some of their favorite capabilities. Primera will not include the Adaptive Optimization Technology that 3PAR uses to tier data between hard disks. Some of the configurability of 3PAR is not available as well. Beta testers have found that it is taking an adjustment to get used to Primera doing the work for them vs having to do ongoing adjustments.
In today’s world, IT professionals are looking for something that eliminates the time needed to manage infrastructure. Primera helps consolidate and simplify. The main concerns for most organizations are availability and safety of one’s data.
Three Unique Experiences
HPE explained that Primera was built to deliver three unique experiences.
- On-demand experience that ensures infrastructure and data are instantly available.
- Application-aware resiliency: See beyond the storage layer combined with analytics to prevent issues from occurring.
- Predictive acceleration: Combining massively parallel architecture with embedded real-time analytics to ensure that applications and business processes are fast all of the time.
Intelligent Data
Like HPE’s other storage options, Primera will use InfoSight predictive analytics for optimizing performance and reliability. Significant breakthroughs include 93% less time spent on managing storage, the ability to predict and prevent issues, and accelerate application performance.
InfoSight looks at millions of sensors and gathers information to help predict and prevent several issues. An intelligent storage platform will allow for organizations to have agility and performance without hampering IT’s ability to keep up with new demands.
Key Features:
- “All-active” multi-node parallel architecture for resilience and scaling with instant failover capability. Allows for 122% faster Oracle performance.
- Data Services have been decoupled so they can be deployed and restarted independently of each other
- User-upgradable without reboots
- No Tuning Required – every resource is always balanced
- Timeless storage: Data-in place upgrades, free controller refresh, all-inclusive software.
- As-a-Service Experience: customers can pay for only what they use.
Keep It Simple
Simple is key in today’s fast paced IT world. As companies venture into more hybrid environments, it is more important for data to be managed appropriately.
Primera delivers a simple, user experience. It can be self-installed in less than 20 minutes. Storage can be provisioned in seconds. Software can be upgraded by customers in 5 minutes without disruption.
100% Availability
HPE offers a standard of 100 percent availability with this new unit. They promise to credit customers with “up to” 20 percent of the value of their Primera assets in the event of an outage. It comes standard with HPE Proactive Care. There is no requirement of any special contracts or onerous terms.
The product will be available in three array models: HPE Primera 630, HPE Primera 650 and HPE Primera 670. It comes in a 4U chassis with space for up to 24 SSDs, with 16 SAS-based slots and eight NVMe-based slots. The NVMe slots can also be used for storage-class memory such as Intel Optane.
Inside the Primera system are four nodes, each with two Intel Xeon processors. Each node has its own power supply with its own backup battery. The maximum memory that can be initially purchased is 2 terabytes.
HPE plans to sell all-flash and all-HDD models of Primera but customers will not be able to tier data between them. The expectation is that customers will buy the all-HDD models for special use cases such as video surveillance, medical imaging and online archives.
It will be available for order in August 2019. Shipments should be made soon after that. Contact a Zunesis account manager if you would like more information on this storage platform or any other storage solutions for your organization.
I’m sure there will be no surprised reaction when I state that we live in a data driven world. For proof you have to look no further than the people around you as you go throughout your day. Unless you’re hiking through the desert, you’re going to see many people with their heads down, looking at their smartphones as the read and send emails, texts, and tweets. From this same smartphone they will search for information, store notes, review documents, and the list goes on and on (what can’t a smartphone do these day?!)
Here’s the thing about this: All of the information they are creating and accessing is stored somewhere. It is this unabated demand for immediate and reliable data access that has created an unprecedented evolution in Storage technology. And it is the technology industry’s response (an explosion of Storage options) that makes the task of choosing your next Storage Array so difficult.

As businesses look to refresh their storage technology today, they are met with a dizzying menu of features including thin provisioning, deduplication, compression, iSCSI, File, Fibre Channel, All Flash, Hybrid, Tiering, etc.
Of course, the question is which of these features will be relevant for any given environment. The final answers will, of course, vary by environment. However, even after you’ve assessed your needs and ranked your requirements, you will still be faced with an increasingly crowded field of solution options from both established manufacturers and those who are new to the industry.
In my view, if you aren’t including HPE 3PAR StoreServ in your short-list, you may want to reconsider. Not only is HPE an established manufacturer, the 3PAR StoreServ is a mature array family and will match all the features/functionality of its competitors.
What’s more, the family of arrays included in the StoreServ solutions include options that will fit price/performance for Entry level, Midrange, and Enterprise arrays – all of these with the same features and functionalities. Furthermore, you’ll find both All Flash and Hybrid models to suit your requirements.
Here are just a few of the features and functionality you’ll find in the HPE 3PAR StoreServ family:
- Thin Provisioning – Up to 50% reduction in your storage footprint if you are fully provisioned today.
- Dynamic Optimization – The ability to migrate entire volumes to different tiers or RAID levels non-disruptively.
- Adaptive Optimization – The ability to migrate volumes at the sub-volume level based on policies you choose. This too is done non-disruptively.
- Deduplication – The ability to eliminate duplicate blocks and reduce storage footprint, in addition to what Thin Provisioning provides.
- Federation – The ability to migrate volumes/workloads across arrays non-disruptively.
- Priority Optimization – The ability to prioritize IOPS, Throughput, and Latency on a per volume basis.
- Data Encryption – Encryption of data-at-rest.
- File Persona – Serve data via CIFS and NFS directly from the array.
- Fibre Channel and iSCSI
- Detailed Reporting
- Application Integration – For Vmware, Hyper-V, SQL, Exchange, and Oracle.
 And, if you want some validation of how well the 3PAR Family stacks up against its competition, you may want to look at the publications from DCIG, Storage Magazine, Gartner, and TechTarget. Links to these publications and more detailed information about the HPE 3PAR StoreServ can be found at www.hpe.com/us/en/storage/3par.html.
And, if you want some validation of how well the 3PAR Family stacks up against its competition, you may want to look at the publications from DCIG, Storage Magazine, Gartner, and TechTarget. Links to these publications and more detailed information about the HPE 3PAR StoreServ can be found at www.hpe.com/us/en/storage/3par.html.
And, of course, Zunesis is ready to help you understand the benefits of 3PAR for your environment. In fact, if you’d like to spend some time on a 3PAR array, we have three HPE 3PAR StoreServ arrays in our Lab and would love to host you for a POC in our Englewood, CO facility. Please contact us if you are interested in taking a closer look at this technology.
In my last post I wrote about the importance of understanding your current environment before setting out on a search for new data storage solutions. Understanding your Usable Capacity requirements, Data Characteristics, and Workload Profiles is essential when evaluating the many storage options available. Once you have assessed and documented your requirements, you should spend some time understanding the many technologies being offered with today’s shared storage solutions.
Currently, one of the most talked about shared storage technologies is Flash storage. While Flash technology isn’t new, it is more prevalent now than ever before in shared storage solutions. To help you determine whether or not Flash storage is relevant for your environment, I wanted to touch on answers to some of the basic questions regarding this technology. What is Flash storage? What problem does it solve? What considerations are unique when considering shared Flash storage?
In simple terms, Flash Storage is an implementation of non-volatile memory used in Solid State Drives (SSD) or incorporated on to a PCIe card. Both of these implementations are designed as data storage alternatives to Hard Disk Drives (HDD/”spinning disk”). In most shared storage implementations, you’ll see SSD; and that’s what we’ll talk about today.
As you begin looking at Flash storage options you’ll see them defined by one of the following technologies:
SLC – Single Level Cell
MLC – Multi-level Cell
- eMLC – Enterprise Multi-level Cell
- cMLC – Consumer Multi-level Cell
There is a lot of information available on the internet to describe each of the SSD technologies in detail; so, for the purpose of this post, I’ll simply say that SLC is the most expensive of these while cMLC is the least expensive. The cost delta between the SSD technologies can be attributed to reliability and longevity. Given this statement, you might be inclined to disregard any of the MLC solutions for your business critical environment and stick with the solutions that use only SLC. In the past this may have been the right choice; however, the widespread implementation of Flash storage in recent years has brought about significantly improved reliability of MLC. Consequently, you’ll see eMLC and cMLC implemented in many of the Flash storage solutions available today.
Beyond the cell technology, there are three primary implementations of SSD used by storage manufacturers for their array solutions. Those implementations are:
- All Flash – As you might have guessed, this implementation uses only SSD, without the possibility of including an HDD tier.
- Flash + HDD – These solutions use a tier of SSD and usually provide a capacity tier made up of Nearline HDD. These solutions often provide automated tiering to migrate data between the two storage tiers.
- Hybrid – These solutions offer the choice of including SSD along with HDD and can also offer the choice of whether or not to implement automated tiering.
 So why consider SSD at all for your shared storage array? Because SSD has no moving parts, replacing HDD with SSD can result in a reduction of power and cooling requirements, especially for shared storage arrays where there can be a large number of drives. However, the most touted advantage of SSD over HDD is speed. SSD is considered when HDD isn’t able to provide an adequate level of performance for certain applications. There are many variables that impact the actual performance gain of SSD over HDD, but it isn’t unrealistic to expect anywhere from 15 to 50 times the performance. So, as you look at the solution options available for storage arrays that incorporate SSD, keep in mind that your primary reason for utilizing Flash is to achieve better performance of one or more workloads.
So why consider SSD at all for your shared storage array? Because SSD has no moving parts, replacing HDD with SSD can result in a reduction of power and cooling requirements, especially for shared storage arrays where there can be a large number of drives. However, the most touted advantage of SSD over HDD is speed. SSD is considered when HDD isn’t able to provide an adequate level of performance for certain applications. There are many variables that impact the actual performance gain of SSD over HDD, but it isn’t unrealistic to expect anywhere from 15 to 50 times the performance. So, as you look at the solution options available for storage arrays that incorporate SSD, keep in mind that your primary reason for utilizing Flash is to achieve better performance of one or more workloads.
Historically, we have tried to meet performance demands of high I/O workloads by using large numbers of HDD; the more spinning disks you have reading and writing data, the better your response time will be. However, to achieve adequate performance in this way, we often ended up with far more capacity than required. When SSD first started showing up for enterprise storage solutions, we had the means to meet performance requirements with fewer drives. However, the drives were so small (50GB, 100GB) that we needed to be very miserly with what data was placed on the SSD tier.
Today you’ll find a fairly wide range of capacity options, anywhere from 200GB to 1.92TB per SSD. Consequently, you won’t be challenged trying to meet the capacity requirements of your environment. Given this reality you may be tempted to simply default to an All Flash solution. But, because SSD solutions are still much more expensive than HDD, you want to make sure to match your unique workload requirements accordingly. For instance, it may not make sense for you to pay the SSD premium to support your user file shares; but you might want to consider SSD for certain database requirements or for VDI. This is where you’ll be thankful that you took the time to understand your capacity and workload requirements.
When trying to achieve better performance of your applications, don’t let the choice of SSD be your only consideration. Remember, resolving a bottleneck in one part of the I/O path may simply move the bottleneck somewhere else. Be sure you understand the limitations of the controllers, fibre channel switches, network switches, and HBA’s.
Finally, you’ll need to understand how manufacturers can differentiate their implementation of Flash technology. Do they employ Flash optimization? Is Deduplication, compaction, or thin provisioning part of the design? Manufacturers may use the same terminology to describe these features, but their implementation of the technology may be very different. I’ll cover some of these in my next blog post. In the meantime, you may want to review the 2015 DCIG Flash Memory Buyers Guide.
Preparing to Replace Your Data Storage Array
If you’ve been using your data storage array for more than three years, you may be considering a replacement. Perhaps you just received a support renewal notification; or, if you’ve had this array for five years or more, the manufacturer may be announcing its End of Life (EOL). It could be you’ve simply outgrown the capacity and exceeded the performance of your current solution. Whatever the reason, there are some things you can do to prepare for your array search that will help you navigate the myriad of options and more quickly discern which solution is right for your environment.
In the next few blog posts, I will talk about some of the features/functions you’ll find in current data storage offerings and provide my take on how to determine their value for your environment. In this blog post, I want to describe some of the information you’ll need to understand about your current environment before you begin the search. Specifically, you should know what your usable capacity requirements are, the characteristics of the data on the storage system, and the workload profiles your array supports. If you understand these three things, it will be far easier for you to discern what features are important to you and which are not.
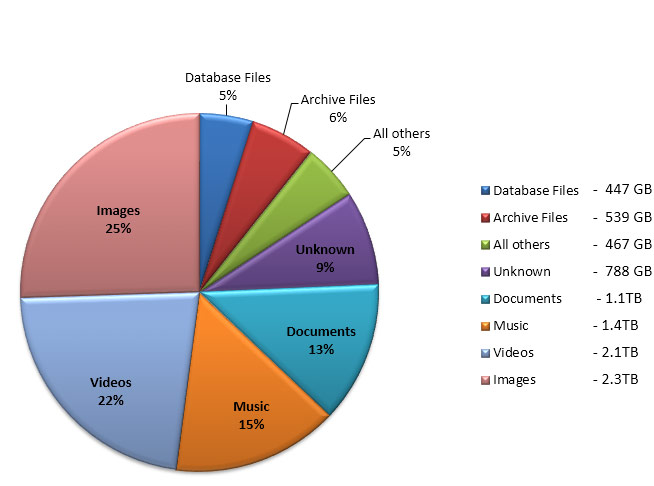 Usable Capacity – While understanding the number, size, and speed of the drives in the current array is useful information, it doesn’t tell the whole story. Most storage arrays utilize some level of RAID protection (RAID 5, RAID 1, RAID 6, etc.); and, consequently, you will need to understand how RAID is implemented on your array and what capacity is provided AFTER taking these RAID levels into consideration. Beyond just capacity, this information can help define the levels of service you currently support for your applications. With this information you’ll be better prepared to have discussions around how a particular solution can provide the same levels of service you currently offer while also meeting your capacity requirements.
Usable Capacity – While understanding the number, size, and speed of the drives in the current array is useful information, it doesn’t tell the whole story. Most storage arrays utilize some level of RAID protection (RAID 5, RAID 1, RAID 6, etc.); and, consequently, you will need to understand how RAID is implemented on your array and what capacity is provided AFTER taking these RAID levels into consideration. Beyond just capacity, this information can help define the levels of service you currently support for your applications. With this information you’ll be better prepared to have discussions around how a particular solution can provide the same levels of service you currently offer while also meeting your capacity requirements.
Data Characteristics – It’s important to know about the data you store on the array. Does the array store Image files, User files (Word, Excel, PDF) Databases, a mix? Additionally, what are the attributes of those files? When were they created? How long has it been since these files were last accessed? Answers to these questions will help you more clearly define storage tiers and give you an indication of how well you could utilize array features like de-duplication, compression, and thin-provisioning. Classifying data in this way can also identify whether or not you have files that could be archived or deleted altogether. Capacity requirements can be significantly reduced in many cases if you discover that you are storing stale data that doesn’t need to be taking up space in your production environment.
Workload Profile – Measuring and documenting performance metrics such as IOPS, Throughput, and Latency, on the array as a whole and on each Storage Volume, will tell you the level of performance your array is being asked to support today. You should also understand the Read versus Write ratio and the Sequential versus Random operations. These metrics should be collected across different periods of a day and a week so that you can account for peaks when sizing a storage solution. It’s also important to associate performance to particular Applications. Understanding these metrics will help determine what storage tier Application volumes should be placed on and which could benefit from active-tiering versus those that should be pinned to a specific tier.

