REST for the Weary – RESTful APIs
As the expression goes, “no rest for the weary.” A lot of us in the IT industry can relate to that statement. We are often needing to work long hours with heavy workloads.
Why is it then, that at least in my observation, many systems and network engineers still have not jumped on the automation train? We’re so busy being busy, that we don’t take the time to save time. Some of us still think RESTful APIs are something that only “devs” use. Luckily for our sanity, many of us are picking up this much needed skill.
If you haven’t played with RESTful APIs yet, and are in IT operations, I highly encourage you to check out RESTful APIs and get some lab time. By sharing some personal experience, I’d like to argue that there really can be “REST for the weary.”(Pun intended)
A slightly better way
I remember before RESTful APIs were something that more vendors were supporting. I had to do write Expect scripts in Linux to do my automation. Really, this was just screen scraping terminal output and brute forcing automation. It was messy at best, especially trying to automate devices that weren’t made for automation.
This wasn’t a whole lot of fun, but it was worth the pain involved since it still saved mountains of time. There was quite a bit of pain with some vendors. They needed weird keystroke combinations before it would allow CLI access even after SSH’ing in. Implementing “CTRL+Y” through an SSH session via script was way more of a headache than you’d think it should be.
Complaining aside, spending time writing Expect scripts was certainly MUCH easier than doing things manually. As an example, in a large environment I previously worked in, my co-workers spent time manually SSH’ing to literally hundreds of switch stacks. They had to run some commands and capture output to save.
I was asked on a regular basis by management to get MAC address/switchport/dot1x info, and other data which could be queried for historical data in a database. This was in preparation for a forklift upgrade on the network. The use case was to get a history of devices, interface information, and all other relevant historical data. Pulling MACs from the cores via uplinks wouldn’t give necessary detail.
This wasn’t an option. We had to go to the switches as a source of truth. The idea was also to compare to data from other sources (the IP-PBX system was one example) in preparation for the upgrade. They wanted to make sure network cut-overs were un-noticed by end users, aside from the downtime to swap equipment of course. I spent quite a bit of time writing and tuning Expect scripts, but still much less than doing things the old fashioned way.
The actual better way
Fast forward to my next job managing literally thousands of server nodes in a high uptime environment. I started getting asked to do things like update BIOS settings ON EVERY SERVER. To make things worse, as software engineering changed their code, they’d ask me to change BIOS settings multiple times. There was no way I was going to iLO into every one of those servers, reboot, wait, press F9 to access system utilities, select BIOS/Platform configuration(RBSU)… etc. Thankfully, I didn’t have to draw a line in the sand and explain that I was unwilling to do this.
After some research, I learned that HPE makes a RESTful API available on their Gen9 and Gen10 servers. Lucky for me, we were using Gen9 servers at the time.
Managing BIOS settings isn’t the only thing you can do by the way. You could probably integrate this into your monitoring system if it allows, for non responsive devices as an example. We’ve all seen servers where the lights are on but nobody is home. They seem dead, but respond to pings…intermittently and with high latency. You could use your monitoring system to poll services, and metrics like CPU and RAM utilization. Then, reboot the server via iLO RESTful API, if it is really locked up. No more waiting for a human to notice alerts, escalate if needed, then reboot the server manually.
One Interface for Integrated Control
HPE Integrated Lights Out (iLO) server management provides intelligent remote control automation through scripting or an API. Gain even more capabilities that go beyond scripting by leveraging one API to manage your complete lifecycle of HPE Gen9 and Gen10 servers—iLO RESTful API.
A single API interface integrates server management components and full compute power. Use it with HPE iLO 4 and iLO 5 to perform remote server provisioning, configuration, inventory and monitoring to industry standards through Redfish API conformance.
This was a game changer. I was able to prepare some standard JSON files with standardized BIOS settings. Then, write a script utilizing HPE’s RESTful API, and push settings described in the JSON file to every server (or subset of servers for testing) with ease.
Some settings still required a reboot to take effect. This was easily handled by scheduled reboots during a maintenance window. I also didn’t need to patch together a solution to script iLO changes with the software equivalent of duct tape and bubble gum, but instead utilized a RESTful API. Something that would have taken FOREVER, was accomplished with ease using something very well documented by HPE.
Give it a try!
Ready to give RESTful APIs a chance on your HPE servers and Aruba networking? Check out these resources:
Not using RESTful API capable servers or networking? The seasoned professionals at Zunesis can assess your environment, and recommend an appropriate refresh path utilizing the latest Aruba networking equipment and Gen10 HPE servers.
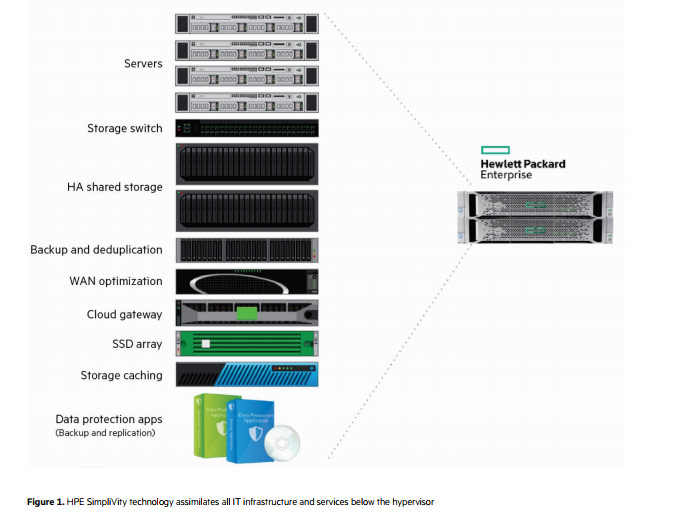
In a competitive world where there are multiple HyperConverged platforms to choose from that will integrate storage, compute, memory and virtualization resources into a small hardware form factor appliance supported by a single vendor, I am seeing a growing demand for one platform in particular, HPE’s SimpliVity.
Over the past three months, I have had three requests to refresh an existing array with SimpliVity. I was also recently asked to bring HPE’s SimpliVity into a large enterprise customer’s datacenter to replace their existing HyperConverged platform. Why are businesses looking at SimpliVity?
There seem to be five key factors that are tipping the scales toward SimpliVity:
- SimpliVity accelerates performance by avoiding unneeded IO
- SimpliVity deduplicates everything once and forever globally across applications
- There is no need to have a minimum of three nodes (like competitive vendors) which helps keep costs down
- SimpliVity has a single point of contact for support, regardless if it’s concerning SimpliVity, VMware or hardware (competitors have multiple hardware vendors)
- SimpliVity comes with an industry best integrated backup solution
SimpliVity simply outshines all competition when it comes to backup/restore. All data is deduplicated, and the restore of VMs in almost immediate, regardless of size, even across different datacenters. In one real life example, a customer had a need to restore 2TB of data quickly. The customer concurrently had one System Administrator start the restore process using a “traditional” backup solution, while another System Administrator decided to try to restore using their newly purchased SimpliVity. End result – SimpliVity restored the file server from their DR location across WAN in about 5 seconds. The System Admin then took the affected partition, attached it to the production file server, replacing the corrupted one, and completed the task in about 10 minutes – at which point they cancelled the traditional restore, which had only hit the 10% mark.
Cost and Speed also plays a large part in customers jumping to move to SimpliVity. The cost savings was quickly realized when one of my customers went from seven cabinets at a colocation facility to half a cabinet for SimpliVity, which integrated everything: network equipment, servers, and back-up appliance. Colocation leasing costs are a fraction of what they had been paying, not to mention the additional savings from lower monthly power bills. The significant gains in speed were even more far reaching. SimpliVity brings faster processors and additional RAM, running a flash array, resulting in a huge IOPS gain. This translated to significant gains in development speed seen in SimpliVity’ s ability to immediately clone and deploy virtual machines. If they have a massive surge in server traffic or have to deploy a new program, all they have to do is click on a template. If they need a new database server or an IIS server, their developer simply has to go in and change host names and IP addresses. If they need additional capacity to boot up a test machine, they can spin up extra development VMs in no time. Their network team can replicate a VM from a template, tweak IPs, host names, firewall rules and load balancer settings, and they are good to go.
Its these real-life examples that create rabid fans of SimpliVity once deployed.
Finally, my customers pointed to the SimpliVity OmniStack Accelerator Card as a key differentiator. The Accelerator Card handles the heavy lifting, delivering the required processing power without the high costs. It’s a uniquely architected PCIe module that processes all writes and manages the compute-intensive tasks of deduplication and compression and allows the x86 CPUs to run customers’ business applications. The card is inserted into a HPE DL380 Gen 9 or Gen 10 server providing ultra-fast write processing and caching services that don’t rely on commodity CPUs. The card contains flash and it is also protected by super-capacitors to allow DRAM to be saved in the event of a power loss, making it extremely reliable.
SimpliVity is a radically simplified and dramatically lower-cost infrastructure platform that delivers on the requirements for scalability, flexibility, performance elasticity, data mobility, global management, and cloud integration that today’s IT infrastructures require.
Read this Case Study from a company in Fort Collins, Colorado on how they were able to decrease complexity and increase efficiency of disaster recovery capabilities, while also reducing expenses when they moved to SimpliVity.
Contact Zunesis today to find out more about SimpliVity.

