HPE Acquisition of Silver Peak
DENVER, CO October 1, 2020 – Hewlett Packard Enterprise (HPE) has completed the acquisition of Silver Peak, an SD-WAN (Software-Defined Wide Area Network) leader. For many years, Silver Peak has been a strong leader in the WAN Optimization and SD-WAN market. Silver Peak is now part of Aruba, a Hewlett Packard Enterprise company.
The acquisition will enhance and strengthen Aruba ESP (Edge Services Platform). This helps to advance enterprise cloud transformation with a comprehensive edge-to-cloud networking solution. It covers all aspects of wired, wireless local area networking (LAN) and wide area networking (WAN).
Steve Shaffer, CEO of Zunesis, a long-time Platinum Aruba and HPE Partner, says “Silver Peak provides a key piece of a comprehensive end-to-end Aruba solution offering. It creates additional value for our clients providing reliable and secure work-from-home and branch office connectivity. Work from home and branch office solutions just got a lot easier to deploy, secure and manage thanks to the combination of Silver Peak and Aruba’s SD-Branch & remote work solutions. All of us at Zunesis are very excited about these new developments.”
WAN Transformation
“WAN transformation is a key component of HPE’s Intelligent Edge and edge-to-cloud vision and growth strategy,” said Antonio Neri, president and CEO of HPE. “Armed with a comprehensive SD-WAN portfolio with the addition of Silver Peak, we will accelerate the delivery of a true distributed cloud model and cloud experience for all applications and data wherever they live.”
“I am very excited to welcome the Silver Peak team to the Aruba family,” said Keerti Melkote, president of Intelligent Edge for Hewlett Packard Enterprise and founder of Aruba Networks. “With the evolving nature of the hybrid workplace, enterprises are looking to extend connectivity to branch locations and enable secure work-from-home experiences. By combining Silver Peak’s advanced SD-WAN technology with Aruba’s SD-Branch and remote worker solutions, customers can simplify branch office and WAN deployments to empower remote workforces, enable cloud-connected distributed enterprises, and transform business operations without compromise.”
As part of the acquisition, Silver Peak founder and CEO David Hughes, will join HPE as the senior vice president of the WAN business within Aruba. “I look forward to leading the new WAN business unit within Aruba and accelerating our customers’ edge-to-cloud transformation initiatives,” said David Hughes, founder of Silver Peak and senior vice president of the WAN business at Aruba. “Digital transformation, cloud-first IT architectures, and the need to support a mobile work-from-anywhere workforce are driving enterprises to rethink the network edge. The combination of Silver Peak and Aruba will uniquely enable customers to realize the full transformational promise of these IT megatrends.”
SD-WAN Technologies
Enterprises are increasingly investing in SD-WAN technologies as legacy WAN architectures incur relatively high costs. They are cumbersome to operate, manage and secure. Aruba and Silver Peak share a common vision and goal to provide simplicity, scalability, and application-awareness at the edge of the network. Aruba’s all-in-one SD-Branch portfolio and remote worker solutions, combined with Silver Peak’s self-driving SD-WAN and WAN optimization solutions, allow Aruba to better address a wide set of customer requirements in order to capitalize on a promising and growing market opportunity.
At the same time, enterprises are also moving applications, including Internet of Things (IOT) and real-time analytics, to the edge of the network. Aruba is uniquely positioned to help organizations to support this network evolution while providing the needed connectivity to Public cloud resources. “We believe HPE Aruba are making all the right moves to help us offer the best and most reliable networking solutions for our customers large and small” says Shaffer. The next few years are going to be very exciting!
About Zunesis
Zunesis, headquartered in Englewood, Colorado has been an HPE Platinum Partner for 16+ years. Zunesis has expert engineers in HPE server, storage and networking technologies along with common software applications like VMware and Microsoft. We serve clients large and small but our sweet spot is the mid-market organization – the heartbeat of the US economy. Our mission is to make the lives of our clients and community better. www.zunesis.com
HPE Discover 2020
Great news IT leaders and friends! HPE is conducting their annual Discover conference virtually and the content looks really good. Many of our clients are wrestling with decreased IT budgets and looking for ways to preserve capital and reduce costs. Often, the very first budgetary line item to get the ax is IT training. I remember clearly how IT training budgets saw reductions or eliminations in the wake of the credit crisis in 2008/2009.
Because HPE Discover is virtual this year, your IT team, managers and leaders can attend at no cost. Our Zunesis VP of Engineering & Consulting recently commented to me after attending HPE’s Aspire conference remotely, “I never had to wait in line for breakfast. I never was late for a session. And, I always had a great seat.” He found the virtual learning experience significantly better. He gained much more knowledge because of the efficiency of the delivery of the material. Some of us still prefer being in the room and the energy that comes from live in-person presentations and engagement, but there are clearly big benefits to providing valuable content virtually.
Impressive Lineup
There is an impressive lineup of content, sessions, technical demonstrations, industry leaders and expert speakers. The current agenda shows 50+ technical training and certification courses; 100+ industry leaders and expert speakers; and, 150+ LIVE and on-demand sessions and demonstrations – AND, none of the sessions are limited by seating capacity. This also could be the most cost-effective way for members of your technical team to get a specific technical certification. Certifications are available at dramatically reduced pricing. The event provides an economical way for members of your team to gain experience and validation of the technologies they need to know to properly manage the HPE technology in your environment.
There are three very interesting leadership & learning tracks that caught my attention:
- The Business of Sports Panel – including Rick Wells, President & CEO of the Golden State Warriors and Steve Kerr – Head Coach
- Performance Under Pressure Panel – how to perform when the stakes are high and the pressure is intense
- Women Leaders in Technology Panel – 3 separate panels hosted by Soledad O’Brien – award-winning journalist, weekly syndicated political show Matter of Fact

Top of Mind Topics
You will also find major content tracks on “top of mind” topics including:
- Business Continuity – this topic probably hits home now more than ever
- Financial Flexibility – creative ways to get what you need or maintain what you have)
- Hybrid Cloud – latest developments in hybrid IT operational technologies
- Data & Applications – protection of data & applications and the evolving use of containers
- Agile Workforce – approaches to making sure your workforce has the information they need, wherever they are
- Digital Transformation – every organization is evolving, but how can we accelerate the things that matter
- Accelerate Research – how are world-class research organizations using technology to speed up important research
- Intelligent Edge – so much is happening at the edge of the network. Find out how IoT and edge computing are rapidly changing the way we think about provisioning and support IT.
We hope you can take advantage of this great opportunity to access valuable information and hear from leaders and experts. If you need any help or support getting registered for HPE Discover, please reach out to us at Zunesis. We would love to help.
HPE Worldwide Ambassador Summit
Over the last several years, I have been lucky enough to be invited to attend the Hewlett-Packard Enterprise Worldwide Ambassador Summit. This is an invitation-only event where invitees learn about the strategy, products and programs HPE is currently working towards. We are asked to provide feedback on what is working, what is not working and how the programs are impacting the channel. There were several takeaways from the event which are summarized below.
Everything As a Service
Everything as a Service. All the executive sessions had the same overall message, HPE is the Edge-to-Cloud Platform-as-a-Service company. They are moving to an Everything as-a-Service model, from the Aruba Intelligent Edge to the HPE Hybrid Cloud. The target is to be open, cloud-native, intelligent, autonomous and secure at every level.
One of the key components to Everything as a Service is Greenlake. Greenlake is a program that brings the cloud experience on-premise. It is a true consumption model that provides Cloud like agility and economics, while keeping control on-premise. The customer achieves many cloud-like benefits. This includes rapid deployment, scalability, and consumption-based economics while maintaining control.
The catalog offers pre-designed, end-to-end solutions along with fully customizable options. Flex Capacity allows you to design and customize your own infrastructure solutions. One can select from a broad range of HPE and partner technologies and services.
Artificial Intelligence
Similar to most industry news, analytics and artificial intelligence (AI) was a major topic. HPE is incorporating AI into every technology, from the edge to compute to storage and networking. AI in the infrastructure is essential in the hybrid cloud world to simplify and reduce the complexity in managing infrastructure and ensure optimal performance and efficient resource use. HPE InfoSight is one of those AI solutions that predicts and prevents problems across the infrastructure stack. It ensures optimal performance and efficient resource use.
Clearpass Device Insight
With the introduction of cloud applications and software, plus the adoption of Internet of Things (IoT) devices, networks have become extremely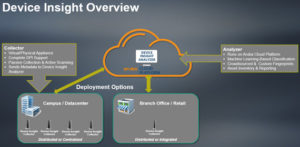 important to business and have become more complex. Aruba ClearPass Device Insight provides visibility across the network and provides the context of all connected devices. With Device Insight, attributes such as device type, vendor, hardware version and behavior and accessed resources are available. This allows the more granular information when creating access policies, reducing security risks and meeting key compliance requirements.
important to business and have become more complex. Aruba ClearPass Device Insight provides visibility across the network and provides the context of all connected devices. With Device Insight, attributes such as device type, vendor, hardware version and behavior and accessed resources are available. This allows the more granular information when creating access policies, reducing security risks and meeting key compliance requirements.
Composability
The last topic we spent a lot of time discussing was Composability. HPE introduced the concept with the introduction of the Synergy platform. They didn’t stop there. Today they also have the Composable Rack and Composable Fabric.
 The Composable Rack can Automate IT operations and deliver applications and services faster. It uses standard HPE Rack mount servers, current management tools, along with the Composable Fabric. This solution enables rapid deployment of your choice of HPE SimpliVity, VMware virtual machines, Red Hat OpenShift containers, or bare metal workloads for new cloud-native workloads. HPE Composable Fabric provides flat, wire-once, and top-of-rack 25G server connectivity. It features programmatic control, easy rack-to-rack scaling, and broad compatibility with existing data center networks.
The Composable Rack can Automate IT operations and deliver applications and services faster. It uses standard HPE Rack mount servers, current management tools, along with the Composable Fabric. This solution enables rapid deployment of your choice of HPE SimpliVity, VMware virtual machines, Red Hat OpenShift containers, or bare metal workloads for new cloud-native workloads. HPE Composable Fabric provides flat, wire-once, and top-of-rack 25G server connectivity. It features programmatic control, easy rack-to-rack scaling, and broad compatibility with existing data center networks.
This fabric not only enables composable element connectivity but also directly affects the integrity and performance of the underlying infrastructure and applications. Traditional, enterprise networks focus on north/south workload traffic between clients and servers. They are not designed to handle the distributed and varied nature of modern scale-out applications that require machine-to-machine communication over the network.
Our solution architects at Zunesis are knowledgeable in all of these areas. Reach out to Zunesis today to find out more about these focus areas.
HPE InfoSight
With the purchase of Nimble, HPE gained a great storage platform. It also gained the valuable asset of InfoSight. InfoSight is an AI-driven predictive analytics tool which enables customers to gain higher efficiency and reliability with smarter, easy to manage infrastructure. HPE InfoSight automatically predicts and resolves 86 percent of issues before a problem is identified.
Since that time, HPE has extended the InfoSight predictive analytics and recommendation capabilities to the HPE Server line This includes Proliant, Apollo and Synergy compute products.
Benefits
InfoSight will enable a smarter, self-monitoring infrastructure. This helps to drive down operating costs. It analyzes millions of sensors across the installed base across the globe. Using this data, it will provide trend insights, forecasting and recommendations, to predict and prevent problems.
HPE storage customers are already enjoying the benefits of HPE InfoSight. They are seeing operational costs decreased by as much as 79 percent. Trouble tickets are resolved in 85 percent less time. Above all, 86 percent of issues are automatically predicted and resolved before a problem is identified.
The Infrastructure for Servers will provide Global Visibility into the Server Infrastructure through the wellness monitoring dashboard. Predictive Analytics on parts failures, and recommendations based on patterns or signs of abnormality will be available to eliminate performance bottlenecks on servers.
Capabilities
A foundational set of capabilities that can be augmented over time has been delivered by the first release of HPE InfoSight for servers.
The Capabilities includes:
1) Predictive data analytics for parts failure
2) Data analytics for server security
2) Global Operational Dashboard with a consolidated view of the status, performance, and health of their server infrastructure. This includes system information, server warranty, and support status
4) Global Wellness Dashboard with a consolidated view of the health of the server infrastructure, including recommendations
5) Recommendations to eliminate performance bottlenecks on servers
6) Support for HPE ProLiant servers, HPE Synergy compute modules and HPE Apollo systems (Gen10, Gen9, and Gen8 with iLO 5 and iLO 4)
HPE Infosight improves the customers infrastructure management experience. When combined with HPE OneView, it can simplify the on-premises experience. HPE OneView provides compute lifecycle management and template driven infrastructure deployment. It transforms the infrastructure to software-defined. This allows customers to deploy infrastructure faster, simplify lifecycle operations and increase productivity.
How to Install
To start using HPE InfoSight for servers, you’ll need to download and install the iLO Amplifier Pack which serves as the aggregation point for the collection of the data for all of the servers. In addition, it passes the health, configuration, and performance data of each server to InfoSight. Should InfoSight need to take any action on the servers, InfoSight will communicate the action to iLO Amplifier Pack to perform the action.
Contact Zunesis to see how InfoSight can improve your current infrastructure.
Improving Higher Availability
Regardless of the organization size, every one of our clients is continually assessing ways to make their IT environment more highly available. Depending on budgets, the level of availability considered can vary widely. But, whatever the budget, improving availability is an important endeavor for all organizations and the right approach is usually multi-faceted.
To be clear, I am not talking about backup/recovery or keeping data offsite in case of disaster. Rather, I’m focusing here on ways to keep systems up even when a part of the infrastructure fails; maintaining continuous operation.
This week, I want to start by listing a few of the more common solutions to achieve higher availability but focus on one that leverages an industry standard. HPE mid-range storage arrays provide an affordable and easy way to deploy solutions for high availability.
Base Level of Availability
The base level of availability for all our clients begins with solutions that provide no-single-point of failure in the primary data center. In many cases, this is as simple as assuring all storage is protected by some level of RAID and that there are multiple paths to the network and to storage. This level of availability also means that all hardware components have redundant fans and power and that they are connected to redundant power distribution units in the rack.
With so many organizations using colocation services today, power redundancy can affordably be expanded to include multiple power grids and generators. So, you can see that even at the base level, providing high availability has multiple facets.
Host/OS Clustering
Usually, the next level of availability is some type of host/OS clustering (Microsoft Clusters, ESXi Clusters, etc.). Again, because the use of colocation services is becoming so prevalent, stretching these clusters across geographic distances is often an affordable consideration. And, since we are talking here about maintaining continuous availability, the latency between sites should be very low to facilitate a stretch cluster.
These types of clusters are often active/active and will serve as failover sites for one another. It is this kind of infrastructure that supports an availability solution from HPE called Peer Persistence.
HPE Peer Persistence
An HPE Peer Persistence solution allows companies to federate Storage systems across geographically separated data centers at metropolitan distances. This inter-site federation of storage helps customers to use their data centers more effectively by allowing them to support active workloads at both sites. They can move data and applications from one site to another while maintaining application availability even if one side goes offline completely.
In fact, Peer Persistence allows for planned switchover events where the primary storage is taken offline for maintenance or where the workloads are simply moving permanently to the alternate site. In any event, the failover and failback of the storage is completely transparent to the hosts and the applications running on them.
This capability has been available on HPE 3PAR StoreServ arrays for over five years. And, now, with the latest release of the Nimble OS (5.1), Peer Persistence is supported on the Nimble Platform.
ALUA Standard
The basis for Peer Persistence is the ALUA standard. ALUA (Asymmetric Logical Unit Access), allows paths to a SCSI device to be marked as having different characteristics. With ALUA, the same LUN can be exported from two arrays simultaneously. Only the paths to the array accepting write to the volume will be marked as active.
The paths to the secondary side volume (the other array) will be marked as standby. This prevents the host from performing any I/O using those paths. In the event of a non-disruptive array volume migration scenario, the standby paths are marked as active. The host traffic to the primary storage array is redirected to the secondary storage array without impact to the hosts.
Components Needed
Whether using HPE 3PAR StoreServ or Nimble, Peer Persistence is possible using certain components. First, you must have two arrays that support synchronous replication. In this case, we are talking about either HPE 3PAR StoreServ or Nimble arrays (3PAR requires another 3PAR and Nimble requires another Nimble).
Beyond that, you’ll need:
- RTT (round trip time) Latency of 5ms or less between the sites
- Hosts that can support ALUA. Those include:
- Oracle RAC
- VMware
- Windows
- HP-UX
- RHEL
- SUSE
- Solaris
- AIX
- XEN Server
- A Quorum Witness – This component is software deployed in a third site that receives ongoing status from each array in the Peer Persistence relationship to help define when a failover needs to take place.
Demo- Please!
At this point, I had planned on providing a drawing and an explanation of how Peer Persistence utilizes the components mentioned above. However, instead I’m including two videos that do a great job of showing the Peer Persistence solution.
Why Peer Persistence?
If you already utilize 3PAR or Nimble in your infrastructure, then you should consider this solution to improve your availability. It is a simple way to achieve high availability utilizing a storage solution with which you are already familiar. If you are considering a storage refresh, Peer Persistence is reason to explore either 3PAR or Nimble as part of your infrastructure.
Zunesis can show you this technology first hand in our lab. And, you can see a case-study on our website where we successfully deployed this solution.
“Endgame”:
- (in chess)- the final stage of a game, usually following the exchange of queens and the serious reduction of forces.
- the late or final stages of any activity.
Superfan Alert
This Friday, Marvel’s Avengers: Endgame premiers in theaters (technically tonight if you were lucky enough to get tickets to the Thursday night screenings). It is shaping up to be the most anticipated film in human history.
Since I am a Marvel superfan, you could take this statement as hyperbole. But with presales ticket figures at over $130 million and one crazy fan even paying $15,000 on eBay for a pair of tickets…I stand by my claim!
It seemed only fitting to write about this massive cinematic event in my blog this week. Besides the fact that it is one of the most prominent topics of discussion as we inch closer and closer to the big premier. “Endgame” also happens to be the “main event” at the IT presentation that Zunesis is hosting in conjunction with Aruba and HPE tomorrow (again…if you were lucky enough to get tickets to our SOLD OUT event)!
If you remember, (which I’m sure you do if you have even the slightest inkling of what these movies are about) when we last saw the remainder of our heroes, they were left sitting helplessly after just witnessing half of the known universe be completely obliterated from existence! How’s that for a bad day?
Like in chess, the leftover Avengers are in the “endgame” with little resources and only the faintest hope of gathering their remaining forces and rallying one last offensive against the enemies of the universe. As exciting as this is and as eager as many of us are to see the conclusion of this epic saga…the whole concept really got me thinking about the other world I live in; the world of IT.
IT Endgame
 What if you, as a customer, got put into a situation where you had greatly reduced resources? What if your data center experienced catastrophic failure and you and your colleagues found yourself in the “IT-endgame”? Wouldn’t you avoid this if you could? Wouldn’t it be nice to have Dr. Strange in your ear telling you where your environment is at, where it has been, and where it will be? Well now you can, with our help!
What if you, as a customer, got put into a situation where you had greatly reduced resources? What if your data center experienced catastrophic failure and you and your colleagues found yourself in the “IT-endgame”? Wouldn’t you avoid this if you could? Wouldn’t it be nice to have Dr. Strange in your ear telling you where your environment is at, where it has been, and where it will be? Well now you can, with our help!
It’s called Recurring Data Center Advisory Service or RDCAS (I’m pushing for “RDSAS”, Recurring Doctor Strange Advisory Service, but nobody will listen to me). It’s the newest professional service that Zunesis offers to our HPE-centric customers. I know that our CEO just wrote his own blog on this topic a few weeks back, but it is a great new offering that we have in our professional services catalog and I really want people to see the value that it brings! And what better way than using the biggest movie on the planet as an analogy?
RDCAS is an advisory service wherein Zunesis will continually review your HPE infrastructure (the frequency of which is based on your company’s personal preference) and give you a documented summarization of our findings after each run-through. We will create an effective maintenance plan for you that details when your required or recommended updates are, processes involved for said updates, and can even download and provide update packages for you. We will monitor your support contracts and even escalate your service tickets with a sense of urgency.

Imagine being able to sit-down with Dr. Strange every quarter and review the entirety of your HPE infrastructure (or as much as you wish to review). You will have an accurate representation of your environment’s performance, OS versions, updates, patches. Wouldn’t it be nice to have an ongoing cadence that improves your uptime and overall infrastructure health. Or would you rather wait and find yourself in the “datacenter-endgame” like those poor Avengers? If you answered “yes” to this question, then Recurring Data Center Advisory Service is the right-fit for you!
I have barely scratched the surface of what the RDCAS can provide. While maintenance and support costs are on the rise (especially in the case of a massive failure), I want all our customers to know that this great service is available. It’s like G.I. Joe said, “knowing is half the battle”.
If you want to learn more about RDCAS or how Zunesis can help you with your IT environment, please reach out to a Zunesis or visit our website! Until then, I wish you all a super-heroic Thursday and a MARVELous weekend! “Avengersssss Assemble!’
OT and IT Working Together
At one time, IT managers and staff may have been holed up in corporate headquarters, far away from the action on the factory floor. Now, they find themselves working side by side with their operations technology (OT) counterparts: the operators, engineers, technicians, and maintenance personnel.
Collectively, they’re tasked with marrying existing OT processes with cutting-edge IT infrastructure. The convergence of the IT infrastructure (dedicated storage, compute hardware) with OT processes and systems (heavy machinery, industrial robots, niche factory equipment) has resulted in the creation of cloud-based applications, sophisticated sensors, and other components that make up the Industrial Internet of Things (IIoT).
“The edge is a place where OT has traditionally resided,” says Dr. Tom Bradicich, vice president and general manager, IoT and Converged Edge Systems, at Hewlett Packard Enterprise.
“The manufacturing floor, a wind farm, a submarine, a smart car, a smart city, a power plant, a smart grid, an industrial oil refinery—those are all OT domains. And more and more, IT is moving out there.”
HPE’s Converged Edge Systems
Enter HPE’s Converged Edge Systems to physically bridge OT and IT. With the same compute and storage capabilities as those running in the cloud and data centers, organizations can process full, unmodified enterprise workloads at the edge. This essentially gives businesses a second on-premises environment (along with the traditional data center) and removes the need to move data and workloads back and forth between the edge and the cloud, providing faster response times and lower bandwidth costs.
HPE EL300
Specific to the convergence of OT and IT at the Edge, HPE has introduced the EL300. The EL300’s ruggedized hardware profile and flexible networking, compute, and storage options make it an ideal candidate for deployment in harsh Factory Floor edge environments.
The EL300 is embedded with the new HPE Edgeline Integrated System Manager (iSM) to manage local Edgeline systems complete with edge-specific capabilities such as remote management over WiFi and LTE connections. It is also supported with the Edgeline Infrastructure Manager (EIM), providing a dashboard view into the health of hundreds to thousands of managed systems at a site. EIM can also automate discovery of new devices and be used to easily deploy firmware and software updates.
The EL300’s OT data acquisition, control and networking modules allow Edgeline systems to “talk” with a greatly expanded variety of OT equipment, from IoT sensors to sprawling SCADA systems. Additional tools simplify management of connected equipment, and the workflows that drive them.
They include:
- HPE Edgeline OT Link Platform software, which automatically recognizes and exposes all OT Link certified hardware in the system. It lets non-coders create and supervise data movements using a simple drag-and-drop workload flow designer
- The optional HPE Edgeline Workload Orchestrator (EWO), which provides centralized deployment and management of containerized applications, middleware, and flows.
Stay tuned for more from the HPE Edgeline team as the converged OT and IT systems make configuration and support easier, and by a wider range of people, from OT specialists to trained IT staff.
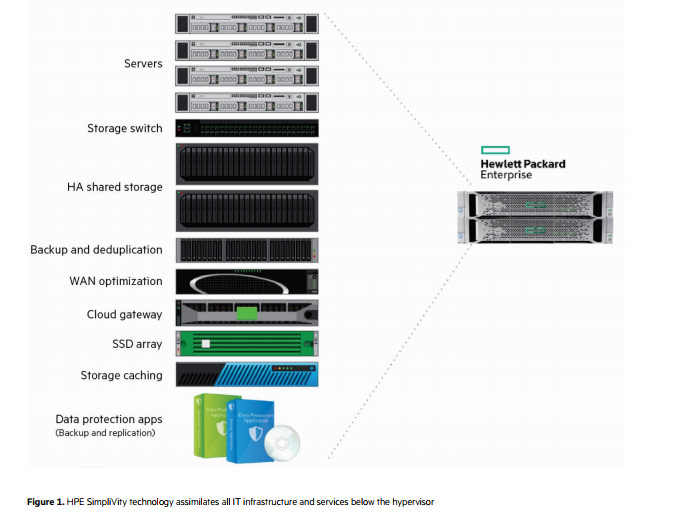
In a competitive world where there are multiple HyperConverged platforms to choose from that will integrate storage, compute, memory and virtualization resources into a small hardware form factor appliance supported by a single vendor, I am seeing a growing demand for one platform in particular, HPE’s SimpliVity.
Over the past three months, I have had three requests to refresh an existing array with SimpliVity. I was also recently asked to bring HPE’s SimpliVity into a large enterprise customer’s datacenter to replace their existing HyperConverged platform. Why are businesses looking at SimpliVity?
There seem to be five key factors that are tipping the scales toward SimpliVity:
- SimpliVity accelerates performance by avoiding unneeded IO
- SimpliVity deduplicates everything once and forever globally across applications
- There is no need to have a minimum of three nodes (like competitive vendors) which helps keep costs down
- SimpliVity has a single point of contact for support, regardless if it’s concerning SimpliVity, VMware or hardware (competitors have multiple hardware vendors)
- SimpliVity comes with an industry best integrated backup solution
SimpliVity simply outshines all competition when it comes to backup/restore. All data is deduplicated, and the restore of VMs in almost immediate, regardless of size, even across different datacenters. In one real life example, a customer had a need to restore 2TB of data quickly. The customer concurrently had one System Administrator start the restore process using a “traditional” backup solution, while another System Administrator decided to try to restore using their newly purchased SimpliVity. End result – SimpliVity restored the file server from their DR location across WAN in about 5 seconds. The System Admin then took the affected partition, attached it to the production file server, replacing the corrupted one, and completed the task in about 10 minutes – at which point they cancelled the traditional restore, which had only hit the 10% mark.
Cost and Speed also plays a large part in customers jumping to move to SimpliVity. The cost savings was quickly realized when one of my customers went from seven cabinets at a colocation facility to half a cabinet for SimpliVity, which integrated everything: network equipment, servers, and back-up appliance. Colocation leasing costs are a fraction of what they had been paying, not to mention the additional savings from lower monthly power bills. The significant gains in speed were even more far reaching. SimpliVity brings faster processors and additional RAM, running a flash array, resulting in a huge IOPS gain. This translated to significant gains in development speed seen in SimpliVity’ s ability to immediately clone and deploy virtual machines. If they have a massive surge in server traffic or have to deploy a new program, all they have to do is click on a template. If they need a new database server or an IIS server, their developer simply has to go in and change host names and IP addresses. If they need additional capacity to boot up a test machine, they can spin up extra development VMs in no time. Their network team can replicate a VM from a template, tweak IPs, host names, firewall rules and load balancer settings, and they are good to go.
Its these real-life examples that create rabid fans of SimpliVity once deployed.
Finally, my customers pointed to the SimpliVity OmniStack Accelerator Card as a key differentiator. The Accelerator Card handles the heavy lifting, delivering the required processing power without the high costs. It’s a uniquely architected PCIe module that processes all writes and manages the compute-intensive tasks of deduplication and compression and allows the x86 CPUs to run customers’ business applications. The card is inserted into a HPE DL380 Gen 9 or Gen 10 server providing ultra-fast write processing and caching services that don’t rely on commodity CPUs. The card contains flash and it is also protected by super-capacitors to allow DRAM to be saved in the event of a power loss, making it extremely reliable.
SimpliVity is a radically simplified and dramatically lower-cost infrastructure platform that delivers on the requirements for scalability, flexibility, performance elasticity, data mobility, global management, and cloud integration that today’s IT infrastructures require.
Read this Case Study from a company in Fort Collins, Colorado on how they were able to decrease complexity and increase efficiency of disaster recovery capabilities, while also reducing expenses when they moved to SimpliVity.
Contact Zunesis today to find out more about SimpliVity.
Network Management Suites available today through HPE
Network management has been around since the dawn of networking. In the early days, companies like Cisco and Hewlett Packard Enterprise (HPE) would create their own proprietary management software to manage their switching products (i.e. Procurve Manager was originally an HPE-only tool until it was updated with limited 3rd party support).
This all changed in the early 2000’s when a protocol called SNMP (Simple Network Management Protocol) was standardized and introduced to switches. This allowed the management plane of the switch to communicate live statistics such as response times, CPU utilization, etc., back to a centralized network management solution in an open-standards manner. It also allowed network admins to have a “single pane of glass” into the basic statistics of their multi-vendor network. SNMP has gone through various revisions to this day but the basic principle remains the same – allowing network admins to manage a multivendor network environment from one tool.
How They’re the Same:
Airwave and IMC both utilize SNMP to communicate with 3rd party devices, and both have an extensive list in the thousands of devices that are supported from 3rd party vendors from Cisco to Netgear.
How They’re Different:
The product differentiation comes down to how these tools will be utilized by the Network Admins:
Airwave
Airwave is directed more at “campus” environments (think carpeted office space, K-12, higher ed campuses, etc.) due to how easy it is to use compared to the more daunting setup involved in IMC. Another reason for this positioning is because Airwave is a much more capable wireless management tool, giving customers much better insight into the health of their wireless network then IMC can provide.
An example of this would be the VisualRF plugin in Airwave. VisualRF provides a real-time view of their RF coverage and client positioning. This visual tool allows network engineers to see their actual RF coverage inside of a building, giving them a good idea of any existing gaps in coverage that they might need to add an additional AP to support. Airwave is licensed per device on the network, and those licenses give you access to the full software suite.
IMC
Intelligent Management Center, or IMC, is committed to being a true “nuts and bolts” engineer tool, even allowing access to IMC’s APIs, giving customers the freedom to program their own modules within the platform. For this reason, HPE has started positioning this as more of a Datacenter focused “NOC” (networks operation center) tool.
Administrators can get much more in depth with the types of SNMP traps, alarms/alerting, and even the types of information that can be reported on with the tool. The initial setup is much more intensive than an Airwave deployment, and the interface is much less user friendly than Airwave, However, you can get extremely detailed real-time information out of the IMC platform – especially when it’s monitoring Aruba (ProCurve) or Comware switches. An example of this would be the QoS Manager plugin, which gives network administrators the ability to define a new global policy or make changes to an existing QoS policy and push those changes out to the network.
Currently, the only wireless management that IMC supports is for the legacy HPE wireless solutions MSM and Unified Wireless, but an “Airwave plugin” is in the works to bridge the gap to include Aruba wireless deployments. IMC is sold as modular software – the base platform is very capable; but to get some specific functionality, such as the QoS Management, you need to license the module. IMC is also licensed by device count in the base platform; however, some of the modules have different licensing schemes.
HPE has committed to continued product development on both platforms. As of right now, there are no early warning signs of one product cannibalizing the other. Choosing which product is rightyou’re your environment really depends on what you are hoping to get out of the platform. If you’re looking for something that’s easy to use with awesome built-in reporting, look into Airwave. If, on the other hand, you need an extremely customizable tool that can report on virtually any network statistic under the sun, IMC is your ticket. If you’re not sure which is the better fit for your organization, we are happy to sit down, discuss your needs, and dive deeper into the platforms in order to make the appropriate recommendation.
Over the last several months, Hewlett Packard Enterprise (HPE) has introduced new some technologies and, of course, new terminology to go along with them. We now have terms like “Composable Infrastructure” and the “Virtual Vending Machine” to understand. Here’s a quick overview of what these trendy new terms mean:
Composable Infrastructure
 This is HPE-speak for one of their newest products: Synergy. Recognized as the infrastructure of the future, Composable Infrastructure is designed to run traditional workloads as efficiently as possible, while accelerating value creation for a new breed of applications that leverage mobility, Big Data, and cloud-native technologies. This is a new approach to traditional architecture is built to allow the IT organization to work with the speed and flexibility of the cloud in their own data center.
This is HPE-speak for one of their newest products: Synergy. Recognized as the infrastructure of the future, Composable Infrastructure is designed to run traditional workloads as efficiently as possible, while accelerating value creation for a new breed of applications that leverage mobility, Big Data, and cloud-native technologies. This is a new approach to traditional architecture is built to allow the IT organization to work with the speed and flexibility of the cloud in their own data center.
For more information, visit the official site here.
Virtual Vending Machine
 Recently, HPE announced the new Hyper Converged 380. This is based on one of their most proven technologies, the ProLiant DL380 Gen9 platform; and it introduces the concept of a Virtual Vending Machine. The solution integrates compute, storage, and virtualization. It features simplified upgrades, increased uptime and service levels. The new software-defined intelligence layer provides advanced analytics and reduces the costs to start, scale, and protect. The HC380 puts you on a direct path to composability.
Recently, HPE announced the new Hyper Converged 380. This is based on one of their most proven technologies, the ProLiant DL380 Gen9 platform; and it introduces the concept of a Virtual Vending Machine. The solution integrates compute, storage, and virtualization. It features simplified upgrades, increased uptime and service levels. The new software-defined intelligence layer provides advanced analytics and reduces the costs to start, scale, and protect. The HC380 puts you on a direct path to composability.
Check out the site for more details.
Ask us for more information about either of these new technologies and how they can fit into your greater data center roadmap.

